type
status
data
slug
summary
tags
category
password
icon
Abstract:
IR是信息获取的主要手段,在对话、问答、推荐系统中均有应用。IR从最初基于term的方法演化到基于高级神经网络的方法后,仍然受到数据稀疏性、准确性等挑战。在chatgpt和gpt-4为代表的大模型的兴起后,IR系统也尝试使用大模型。本综述整理了现有的方法,并探索未来的方向。
INTRODUCTION:
信息获取是日常基础需求之一,除了搜索引擎(百度、谷歌、bing),信息检索在对话系统、问答系统、图像搜索等领域也扮演着重要的角色。
信息检索系统的核心是检索,需要从文本、图像、音乐等等不同类别的信息里找到和用户需求相关的内容。本摘要聚焦在文本检索系统中,query和检索doc的相关性由两者的匹配分衡量。IR系统的效率非常重要,为了提升用户体验,常常从上游(查询query改写)和下游(排序、Reading)两个方面增强检索性能。
IR系统图示如下,其中rerank阶段只对检索到的有限doc集排序,需要使用复杂的模型来保证检索效果;reader阶段是对检索到doc进行总结,以给用户提供一个简明的答案。在传统的IR系统中,通常由用户最近对检索结果进行总结,但在new Bing等新IR中,这一步是必要的。
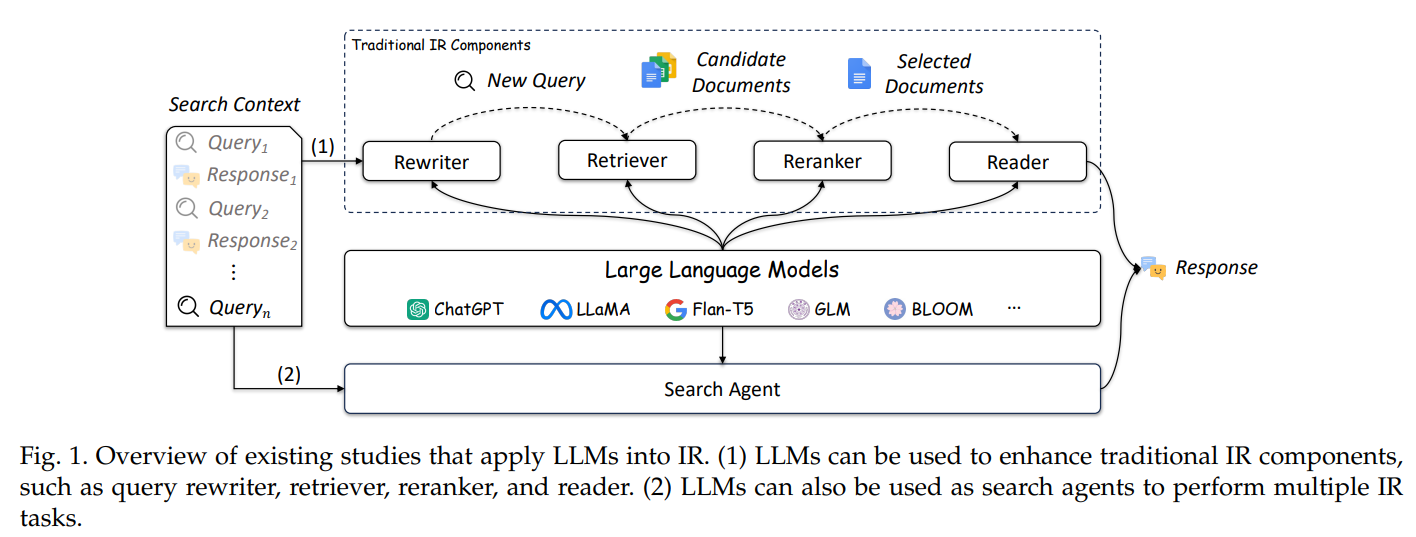
作者收集并将持续更新LLM应用于信息检索的相关论文和代码,地址在 https://github.com/RUC-NLPIR/LLM4IR-Survey。如上图所示,大模型可以应用于IR系统的多个步骤。
BACKGROUND
IR系统
IR 系统早期使用的是布尔模型,通过布尔逻辑运算符来组合查询并检索满足特定条件的文档;后来,基于词袋模型的向量表示方法被引入IR系统,查询query和候选doc通过词袋模型表示成稀疏向量,然后通过计算向量相似性来评估查询结果和query的相关性;再之后,神经网络IR出现,依托神经网络强大的表征能力,IR系统的效果取得了显著的提升。
IR步骤可以被划分成query改写、检索、重排序和reader四个阶段,如上图所示,这四个阶段都可以应用LLM。
query改写:query改写通过修改或重写用户的输入query,可以改善query的准确度和表示能力。这一步骤的主流方法是query扩写。
检索:主要用于查询doc的召回。检索阶段早期使用的词袋模型鲁棒、高效,随着神经网络IR的兴起,流行做法变成了抽查询query和候选doc中提取高维稠密表示并计算内积作为相关性打分的方式。
重排序:检索阶段平衡了效果和效率,重排序阶段主要保障检索的质量,会采用比传统向量内积更复杂的方法,以得到更好的排序效果。此外,重排序阶段还需要设计特定的策略,来满足不同用户的需求,比如个性化和多样性需求等。
reader:reader是随着大语言模型快速发展起来的一个模块,它实时理解用户意图,并根据检索结果动态生成响应。相较于传统的给用户呈现一个候选文档列表的方式,reader模块以人类获取信息的方式组织检索结果。为了提高结果的可信度,将参考文献集成到生成的结果中是该模块的一种有效技术。
LLM
LM可以做文本生成,大量的自然语言处理问题可以被表示为文本到文本的格式,使得用LM解决NLP问题成为一个可行的方案。LM的发展经历了统计语言模型->神经网络语言模型->预训练语言模型的阶段。统计语言模型应用马尔科夫假设基于文本的前面token预测后续的token;神经网络语言模型用神经网络建模文本序列的似然,并使得表示学习容易实现。ELMo首先提出用双向LSTM模型结构学习词的语义表示,并在下游任务重微调;类似地,BERT在大语料上预训练了transformer的encoder。这些研究开创了“预训练语言模型-PLM”领域,并使得先预训练再微调的范式成为主流的方法。沿着这条线,各式各样的生成式预训模型被提了出来并用在了包括文本摘要、机器翻译、对话在内的多种领域,比如GPT-2、BART、T5等等。近来,研究者们发现增大预训练语言模型的规模可以提升下游任务的性能,所以研究转向了大语言模型LLM。
现有的LLM从模型结构划分,可以分为encoder-decoder机构和纯decoder结构,encoder-decoder将输入表示成一个向量,并基于向量解码得到生成的文本;纯decoder结构以GPT为代表,使用self-attention配合diagonal-attention-mask 从左到右生成文本。不同模型和结构的关系如下图,GPT-J、BLOOM、OPT、Chinchilla、LLaMA和gpt的结构相同,训练数据有差异。
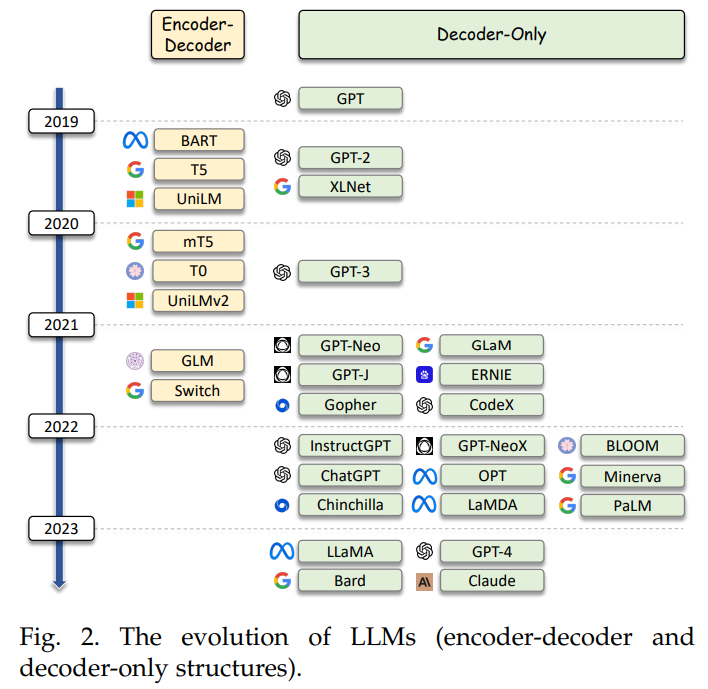
LLM用于信息检索可以采用 in-context learning (ICL) 和 parameter-efficient fine-tuning方式。ICL不需要调整LLM的参数,是LLM应用于信息检索领域的最普遍方式。parameter-efficient fine-tuning的目标是在保持模型性能的同时降低模型训练的参数量, LoRA 是这个方向上普遍使用于开源大模型微调的方法。
重写阶段
两个检索范式
Ad-hoc检索
- 类似于图书馆里的书籍检索,即书籍库(数据库)相对稳定不变,不同用户的查询要求是千变万化的。这种检索就称为ad hoc。基于Web的搜索引擎也属于这一类。
题外话:还有一类IR,称为routing或filtering,,用户的查询要求相对稳定。在routing中,查询常常称为pro file,也就是通常所说的兴趣,用户的兴趣在一段时间内是稳定不变的,但是数据库(更确切的说,是数据流)是不断变化的。这种任务很象我们所说的新闻定制什么的,比如用户喜欢体育,这个兴趣在一段时间内是不变的,而体育新闻在不断变化。
应该说,ad hoc和routing代表了IR的两个不同研究方向。前者的主要研究任务包括对大数据库的索引查询、查询的扩展等等;而后者的主要任务不是索引,而是对用户兴趣的建模,即如何对用户兴趣建立合适的数学模型。后者称为routing是很有道理的,因为不断到来的数据流根据用户的兴趣被分发到不同的用户中去,类似于网络中的路由寻径过程。
- 查询重写的主要目标是检索与用户的信息需求更加一致的文档集合。
- LLMs用于重写阶段有以下优势:
- 更好的语义理解性。LLMs的深语义理解优势有助于捕捉查询query的意图和上下文信息;
- 更广域的知识。LLM拥有广泛的知识,使他们能够从广泛的概念、事实和信息中汲取经验。这些知识使他们能够利用对各种主题的理解,生成相关的、上下文适当的查询重写。
- 不依赖于第一遍检索。传统的伪相关反馈(PRF)方法检索一组伪相关文档作为源来细化原始查询。然而,伪相关反馈集中不相关结果的存在会引入噪声,并可能损害检索性能。相反,LLM可以直接基于原始查询生成查询重写,这独立于第一次通过检索,并避免了潜在的噪声的干扰。
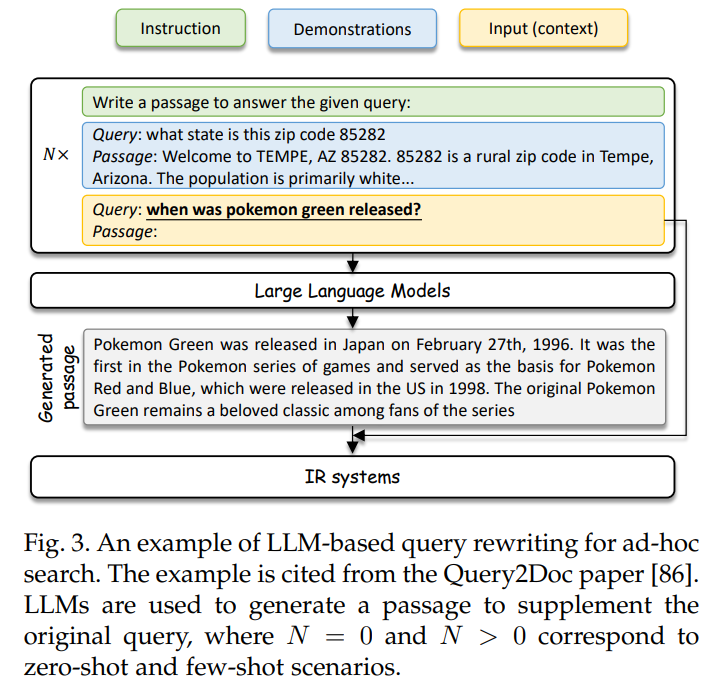
- LLMs用于Ad-hoc检索阶段的方式:输入查询query,LLM生成doc,生成的doc和query组成新的query输入的查询系统中进行信息检索。这样做是因为生成doc中的包含的额外细节信息。如下图中query是when was Pokemon Green released,LLM生成的doc中补充了细节“Pokemon Green was released in Japan on February 27t”
对话式搜索
对话式搜索有助于澄清用户的检索意图。LLMs用于对话式搜索主要是借助大模型的两个能力:
- LLM具有强大的上下文理解能力,使其能够更好地理解用户与系统之间多回合对话的文本中用户的搜索意图;
- LLM具有强大的生成能力,可以模拟用户和系统之间的对话,从而促进更稳健的搜索意图建模。
LLMs用于对话式搜索有个工作叫LLMCS-Large Language Models know yourContextual Search intent:
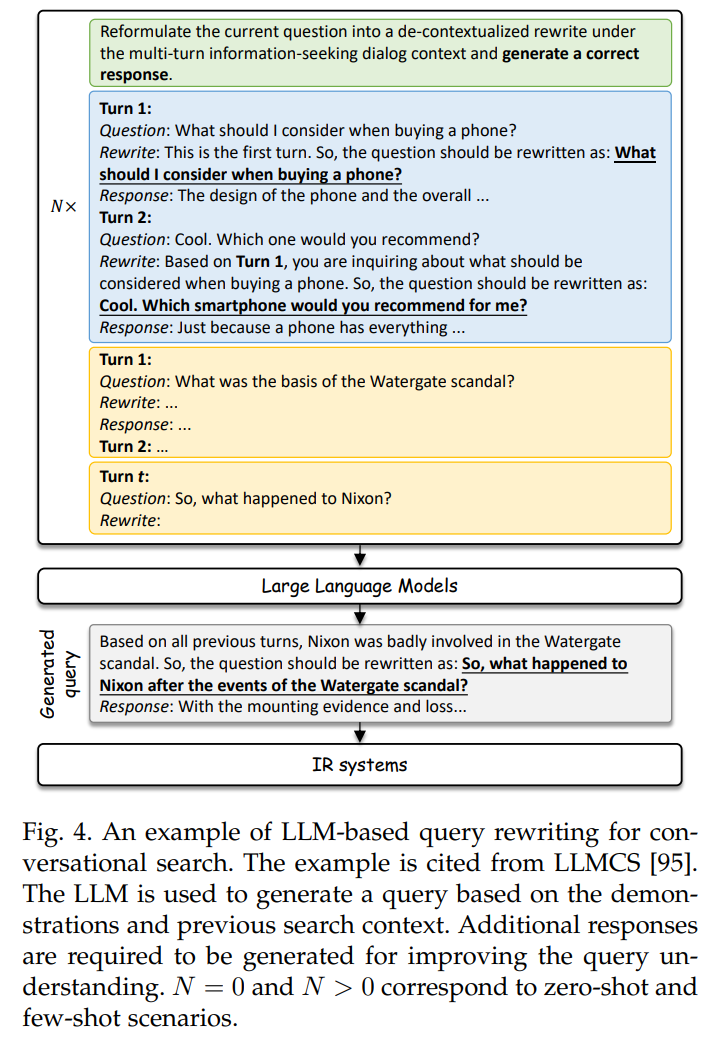
上述图示中有个地方有疑问:第二轮问的是买手机应该考虑哪个方面,重写后变成了推荐哪个智能手机?大模型引进的错误如何解?
数据层面
使用LLM的内在知识,不引入新数据
使用领域特定数据增强LLM的能力
- LLM可能生成幻觉或者无关的query,引入领域数据来解决这类问题。
- 做法包括两种
- 将query和文档合并作为prompt输入LLM;
- 结合LLM生成的相关性反馈(GRF)和伪相关反馈(PRF)
- GRF能提供第一遍检索不包含的信息;
- PRF将查询限制为包含在目标语料库内的信息。
方法
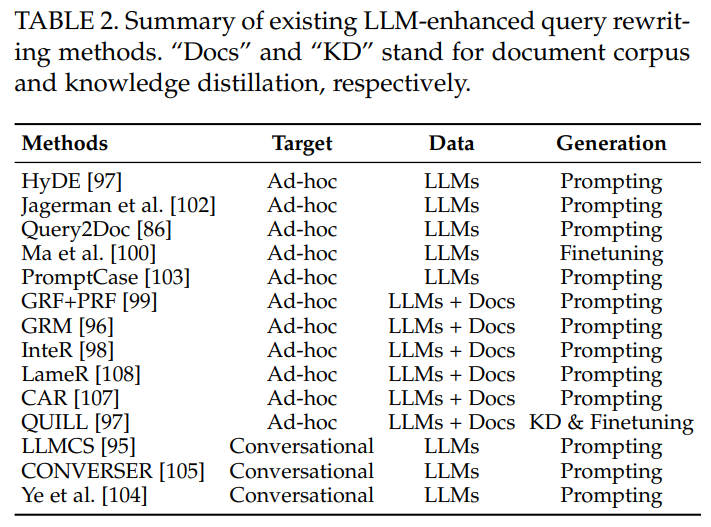
主流方法有三种:
- 最流行的方法是prompt,设计特定的prompt或输入结构,让语言模型生成预期的输出。模型结构不变,模型参数不变。
- 在特定领域微调LLMs;模型结构不变,模型参数变化。
- 知识蒸馏;模型参数和结构都发生变化,用小模型近似大模型的效果。
prompt方法
- zero-shot prompt-零样本。只依赖模型自身对输入query的理解能力生成文本,是一种简单有效的query重写方法。
- few-shot prompt-少样本。即上下文学习( in-context learnin),通过输入有限的示例,让模型具有适应特定任务或场景的能力。
- Chain-of-thought prompt-思维链。给模型提供一系列指令或部分输出,以让模型做更深入的思考。对话式搜索中,query重新是通过多轮对话完成的,ad-hoc搜索因为只有一轮输入query,只能用简单粗糙的方式实现思维链prompt。
微调模型
微调使用领域数据再次训练预训练好的LM,微调后模型的参数会发生变化,其在特定任务、领域上的query重写能力得到增强。微调模型的代价很高。
知识蒸馏
QUILL提出了一种两阶段蒸馏方法。首先有一个训练好的检索大模型profersser、一个普通的teacher大模型和一个基于BERT的student模型,第一个阶段对检索大模型进行蒸馏得到teacher大模型,第二个阶段对teacher大模型蒸馏得到student模型,然后用student模型做在线服务部署。
疑问:为啥不直接从profersser蒸馏得到BERT?需要读QUILL论文。(QUILL: query intentwith large language models using retrieval augmen-tation and multi-stage distillation)
检索阶段
LLM用不检索阶段有两种方法:用LLM生成检索结果;用LLM增强模型结构。
LLM生成检索结果
鉴于搜索数据的质量和数量,关于如何通过LLM提高检索性能,有两种普遍的观点。第一个视角围绕着搜索数据优化方法,这些方法专注于重新制定输入查询,以精确地呈现用户意图。第二个视角涉及训练数据扩充方法,该方法利用LLM的生成能力来扩充密集检索模型的训练数据,特别是在零样本或少样本场景中。
搜索数据优化
该领域的研究工作主要集中在使用LLM作为查询重写器,旨在优化输入查询,以更精确地表达用户的搜索意图。除了查询重写之外,一个有趣的探索途径是使用LLM通过精炼冗长的文档来提高检索的有效性。
训练数据扩展
检索模型是监督学习模型,需要训练数据(query和doc)和label(doc和query是否相关),因为doc一般是一个相对固定的集合,故数据增强从doc中生成伪query和生成label两个方向考虑。

生成伪query
先收集一些query和对应doc的pair,再给出一个待生成query的doc,将pair和doc一起作为LLM的输入,则LLM可以生成针对该doc的query。为了保证生成query的效果,可以在之后再放一个训练好的模型进行过滤。即generating-then-filtering” 范式。
生成label
在query和doc容易获取、但label不容易得到的场景,比如问答类,可以使用LLM针对query和doc生成概率分布,再配合正则化过程将概率分布转化成label。
用LMM增强模型结构
LLM具有很好的文本编码和解码能力,可以用于query和doc的理解。LMM增强检索模型结构有两种做法:基于编码器的检索模型和生成式检索模型。
基于编码器的检索模型
- 将LLM用于检索任务中的文本编码器;
- 设计任务相关的prompt,比如引入问题、领域、意图等信息。
生成式检索模型
- 传统的IR系统包括“index-retrieval-rank” 三个阶段,生成式检索模型用一个单一的模型针对查询query直接生成doc。做法包括微调大模型和prompt大模型两种。
- DSI是一个用检索数据对预训练的T5模型进行微调的方法,该方法对查询query进行编码,并对doc进行解码以得到查询结果。为了保证得到的doc真实有效,DSI使用多有的doc的ID构建字典树,并使用beam search进行解码。
- prompt大模型是直接让大模型生成针对输入query的文档url。LLM-URL模型是本方向的一个工作,模型用GPT-3 text-davinci-003模型生成候选url,然后设计正则化表示从候选中提取有效的url。
排序阶段
LLM用于排序阶段有三种做法:微调大模型、prompt大模型和使用大模型进行训练数据增广。
微调大模型
- 因预训练时缺乏排序意识,LLM不能恰当的评估查询-文档的相关性,也无法全面理解rerank任务。通过在任务特定任务的排序数据集上进行微调,LLM可以在排序任务上获得更好的性能。
- 这个阶段的微调有两种做法:将LLM微调为生成模型和将LLM微调为排序模型。
微调为生成模型
- 使用生成任务的loss优化LLM。
- 排序模型做法:训练阶段微调LLM,针对query-doc对,输出一个单一的信号,比如是否相关的“是”或者“否”;推理阶段,将输出单元的logit值作为query和doc的相关性打分,并按照打分排序。
- DuoT5模型将三元组(q,di,dj)作为输入,在训练结果,针对查询q,如果文档di的相关性高于dj,则label为true,否则为false;在推理阶段,对于查询q和任何一个di,枚举所有的dj,使用函数对所有dj的结果聚合得到di的相关性打分si,即可进行排序。
微调为排序模型
- RankT5可以针对输入的query和doc对直接生成相关性打分,模型训练时用pairwise或listwise损失。
prompt大模型
- LLM参数太大不好微调,prompt希望通过利用LLM的输入指导能力提升模型的排序能力。
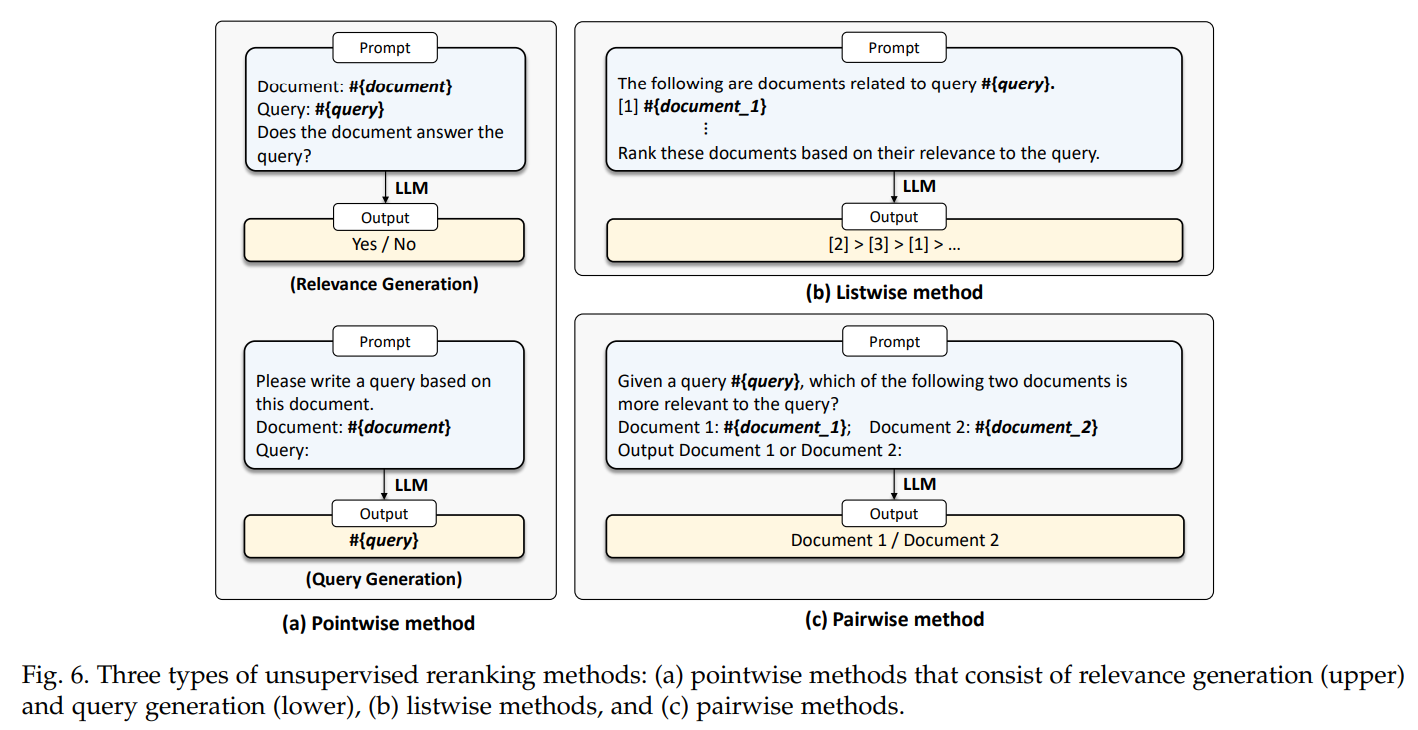
- 做法有三种:pointwise、listwise、pairwise。
pointwise
- 分为生成相关性和生成query两种;
- 对于相关性,输入query和doc的pair,训练时label是“yes”或者“no”,推理时是使用输出单元的概率输出计算相关性score。
- 对于生成query,直接将doc输入LLM,设计合适的prompt话术,让LLM输出query。
listwise
- 将query和多个doc输入LLM,让LLM对多个doc进行排序。
- 受LLM输入长度限制,方法采用了滑动窗口策略,每次对候选文档的子集进行排序。
- 只有基于GPT-4的模型有比较好的效果,在小一些的LLM上效果低于许多监督方法。
- 排序效果对prompt中候选doc输入的顺序敏感。
pairwise
- pairwise比listwise简单。
- pairwise排序prompt让LLM判断一个doc是不是比另一个doc更相关,然后设计了几种排序算法来利用这种pair结果对整个文档列表进行重新排序。
LLM用于训练数据增广
- ExaRanker使用GPT-3.5生成检索数据集的解释,然后训练seq2seq排序模型用于生成相关性标签和解释。
- InPars Light通过prompt大模型输入doc生成query。
reader阶段
鉴于LLM在语言理解、抽取和文本数据处理方面的能力,研究人员尝试将IR系统的范围从内容排序扩展到答案生成。reader是在这一发展过程中引入的模块,通过该模块,IR系统可以直接向用户呈现结论性的结果,而之前的IR是给用户提供文档列表。
被动式reader
- 用查询query检索到的文档或IR系统生成的文本作为LLM的输入,让LLM输出目标文本。因LLM和IR系统是独立的,LLM充当IR系统文档的被动接收者,故这种方式称为被动式。
- 一次检索reader:将检索到的头部doc输入到LLM中生成答案。
- 周期检索reader:在生成答案的过程中,每隔一定的token或sentences,就调用一次检索。
- 非周期检索reader:预先定义一个阈值,在生成答案的过程中如果生成的token或sentences置信度低于阈值,使用IR系统对正在生成的句子进行检索,同时删除低这个低概率句子。
主动式reader
- prompting大模型,使得大模型在生成答案的过程中调用搜索。
- 通过强化学习框架训练大模型调用搜索。
未来工作
- 当前LLM和IR相结合的工作还只是初级阶段,未来潜在的方向还包括 索引、用户建模、匹配或排序、评估、交互等。
- 索引:探索构建生成检索增量索引的方法;设计实现针对多模态检索的LLM。
- 用户建模:增强query理解;提高个性化搜索能力;提升对话式搜索。
- 匹配或排序:降低LLM时延;制定适用于排序任务的LLM;IR框架演进。
- 评估:制定合理的评估指标和测试集。
- 交互:用户和IR系统的交互。
总结
LLM因为强大的语言理解和生成能力,可以被应用在IR系统的多个模块中:
- 在查询重写领域,LLM已经证明了它们在理解歧义或多方面查询方面的有效性,提高了意图识别的准确性。
- 在检索方面,LLM通过在查询和文档之间实现更细微的匹配,同时考虑上下文,提高了检索的准确性。
- 在重新排序领域中,LLM增强模型在重新排序结果时考虑了更细粒度的语言细微差别。
- IR系统中阅读器模块的用途代表着生成全面响应而不仅仅是文档列表的重要一步。LLMs与IR系统的集成带来了用户参与信息和知识的根本变化。